AI & Chat
Multi-provider LLM support with real-time streaming, automatic context management, and a fully customizable prompt system. Switch between 10 models from three providers without changing a line of code.
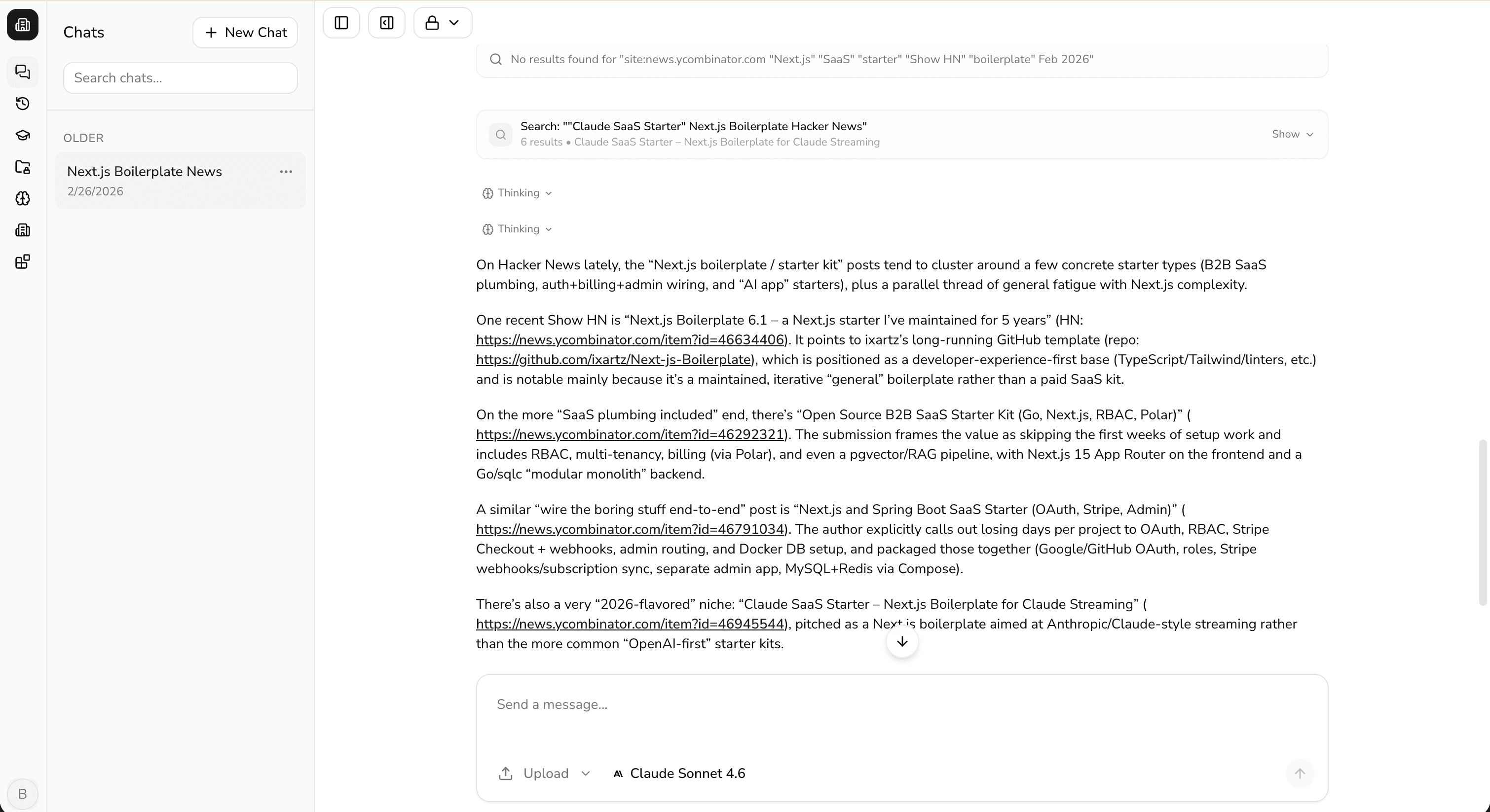
Full-featured chat interface with real-time streaming, web search, and file attachments.
Multi-provider model registry
A unified provider registry aggregating 10 models from Anthropic, OpenAI, and Google with context windows up to 1M tokens. Helper functions for model selection, display labels, provider grouping, and descriptions.
- Anthropic: Claude Opus 4.6, Sonnet 4.6, Sonnet 4.5, Haiku 4.5 (200K context each)
- OpenAI: GPT-5.3, GPT-4.1-mini, GPT-5.2, GPT-5.4 (400K–1M context)
- Google: Gemini 3 Pro, Gemini 2.5 Flash Lite (200K–1M context)
- 6 models support native sandboxed code execution
- UI model catalog with display labels and provider grouping
Real-time streaming
The chat API endpoint streams AI responses in real time using the Vercel AI SDK. Supports up to 30 sequential tool-use steps per request, with file parts validated against 14 MIME types.
- Server-sent event streaming with the Vercel AI SDK v6
- Up to 30 sequential tool-use steps per request
- File parts validated against 14 MIME types with presigned URL hydration
- Auto-resume streaming on page navigation
- Max 600s request duration for long-running tool chains
Automatic context compaction
Long conversations are automatically summarized to stay within model context windows. Older messages are compacted into a summary while the last 6 messages are always preserved verbatim.
- Triggers when token usage exceeds 40% of model context (min 50K tokens)
- Last 6 messages always preserved verbatim
- Summaries cached in Redis with 7-day TTL for reuse across requests
- Hierarchical re-compaction: only new messages re-summarized on top of existing
- Stale compactions auto-detected and discarded when messages are deleted
Customizable system prompts
Centralized prompt configuration with safety guidelines, formatting rules, knowledge cutoff awareness, and specialized prompts for code generation and spreadsheets.
- Main system prompt injects datetime, tool guidelines, and stored memories/skills
- Safety: refusal handling, legal/financial disclaimers, and user wellbeing
- Auto-generates 2–5 word chat titles from user messages
- Specialized prompts for Python code generation and CSV/spreadsheet creation
- Real-time date awareness with configurable knowledge cutoff
Enforcement pipeline
Every chat request passes through a full enforcement chain before reaching the AI. Authentication, ownership, subscription status, rate limits, and token budgets are all checked in sequence.
- Auth → ownership → subscription → rate limit → token budget → compaction → stream
- Rate limiting: 10 messages per 60 seconds (sliding window via Upstash)
- Token budget: 1M tokens per subscription period with decrement tracking
- Structured error codes: 400, 401, 403, 429, 503
- Usage events logged with org/team/model/token metadata
Supported models
All models are ready to use. Users pick from a searchable model selector grouped by provider directly in the chat UI.
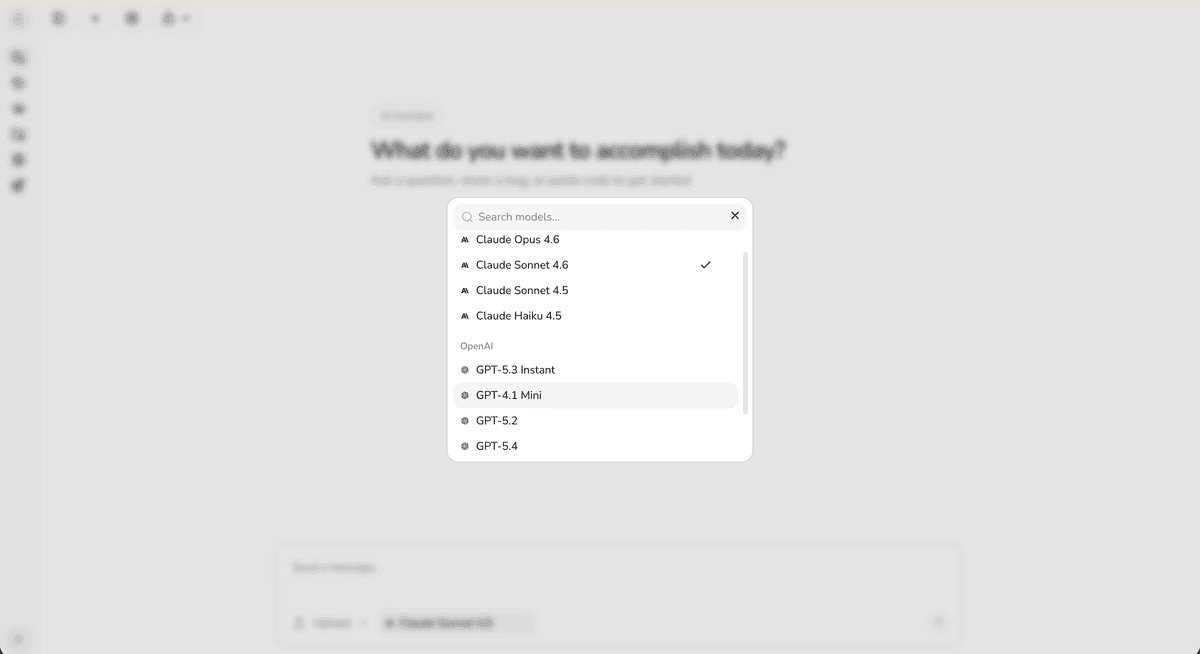
Searchable model selector grouped by provider.
| Model | Provider | Context | Note |
|---|---|---|---|
| Claude Opus 4.6 | Anthropic | 200K | Default chat model |
| Claude Sonnet 4.6 | Anthropic | 200K | — |
| Claude Sonnet 4.5 | Anthropic | 200K | — |
| Claude Haiku 4.5 | Anthropic | 200K | Artifact generation |
| GPT-5.3-chat-latest | OpenAI | 400K | — |
| GPT-4.1-mini | OpenAI | 1M | Webpage summarization |
| GPT-5.2 | OpenAI | 400K | — |
| GPT-5.4 | OpenAI | 1M | — |
| Gemini 3 Pro | 1M | — | |
| Gemini 2.5 Flash Lite | 1M | Title generation |
Get all of this out of the box.
One purchase. Instant access to the full codebase.